文档搜索
# 不可改变的倒排索引
早期的全文检索会为整个文档集合建立一个很大的倒排索引并将其写入到磁盘。 一旦新的索引就绪,旧的就会被其替换,这样最近的变化便可以被检索到
倒排索引被写入磁盘后是不可改变的
- 它永远不会修改
# 优点
- 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题
- 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升
- 其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化
- 写入单个大的倒排索引允许数据被压缩,减少磁盘IO和需要被缓存到内存的索引的使用量
# 缺点
一个不变的索引也有不好的地方
- 如果需要让一个新的文档可被搜索,需要重建整个索引
- 对一个索引所能包含的数据量造成了很大的限制
- 对索引可被更新的频率造成了很大的限制
# 动态更新索引
如何在保留不变性的前提下实现倒排索引的更新?
- 用更多的索引
- 通过增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引
- 每一个倒排索引都会被轮流查询到,从最早的开始查询完后再对结果进行合并
Elasticsearch基于Lucene,这个java库引入了按段搜索的概念。每一段本身都是一个倒排索引,但索引在 Lucene 中除表示所有段的集合外,还增加了提交点(一个文件,记录所有段)的概念:一个列出了所有已知段的文件
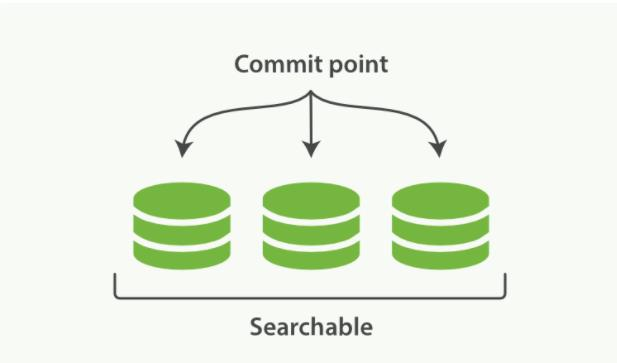
# 按段搜索流程
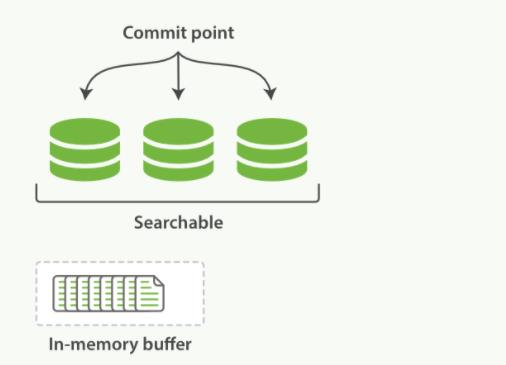
- 新文档被收集到内存索引缓存
- 不时地, 缓存被提交
- 一个新的段,一个追加的倒排索引,被写入磁盘
- 一个新的包含新段名字的提交点被写入磁盘
- 提交点文件也是多个
- 磁盘进行同步,所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件
- 新的段被开启,让它包含的文档可见以被搜索
- 内存缓存被清空,等待接收新的文档
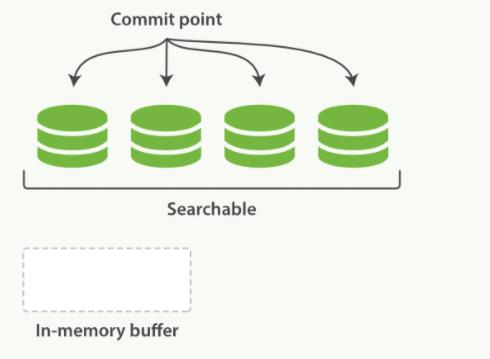
当一个查询被触发,所有已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算。这种方式可以用相对较低的成本将新文档添加到索引。
段是不可改变的,所以既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。取而代之的是,每个提交点会包含一个.del 文件,文件中会列出这些被删除文档的段信息。
当一个**文档被“删除”**时,它实际上只是在 .del 文件中被标记删除。一个被标记删除的文档仍然可以被查询匹配到,但它会在最终结果被返回前从结果集中移除。
文档更新也是类似的操作方式
- 当一个文档被更新时,旧版本文档被标记删除
- 文档的新版本被索引到一个新的段中
- 两个版本的文档都可能会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除
Last Updated: 2022/04/10, 13:57:31