路由计算
# 计算公式
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?
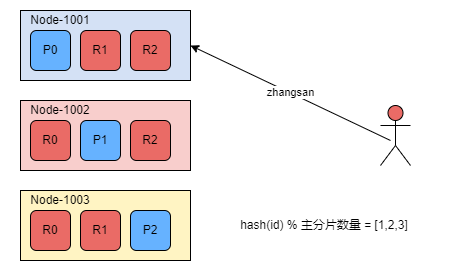
这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
1
routing 是一个可变值,默认是文档的 _id,可设置成一个自定义的值 routing 通过hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是文档所在分片的位置
所有的文档API ( get , index, delete, bulk , update,mget )都接受一个叫做routing 的路由参数,通过这个参数可以自定义文档到分片的映射;一个自定义的路由参数可用来确保所有相关的文档(如所有属于同一个用户的文档)都被存储到同一个分片中
为什么创建索引时确定好主分片的数量并且不能改变主分片数量?
如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了
Last Updated: 2022/04/10, 13:57:31