映射-创建
# 关于映射
索引库 index,等价于数据库 database 映射 mapping ,等价于数据库 database 中的表结构 table
- 创建数据库表需要设置字段名称,类型,长度,约束等
- 索引库需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射 mapping
# 创建映射 PUT _mapping
创建student索引
PUT http://localhost:9200/student
1
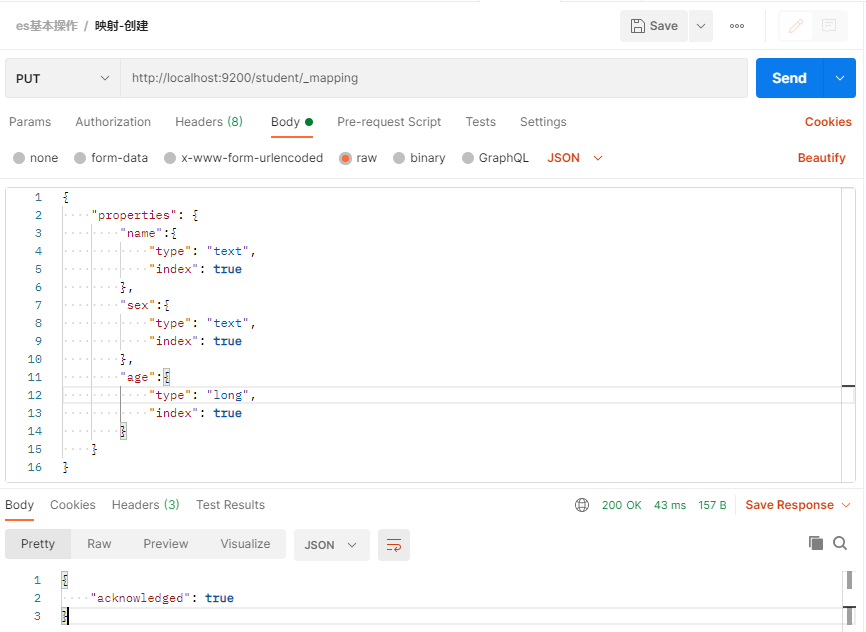
在 Postman 中,向 ES 服务器发 PUT 请求构建mapping
PUT http://localhost:9200/student/_mapping
1
请求体JSON
{
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "text",
"index": true
},
"age":{
"type": "long",
"index": true
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
返回JSON
{
"acknowledged": true
}
1
2
3
2
3
示例
# 创建索引时包含映射
在创建索引的时候包含映射信息
PUT http://localhost:9200/student2
1
请求JSON
{
"settings": {},
"mappings": {
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "text",
"index": true
},
"age":{
"type": "long",
"index": true
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
返回JSON
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "student2"
}
1
2
3
4
5
2
3
4
5
# 映射数据说明
示例
{
"properties": {
"字段名":{
"type": "text",
"index": true,
"store": true,
"analyzer": "ik"
},
}
}
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# 字段名
任意填写,下面指定许多属性,如上例子中的 name ,sex, age
# type
类型
Elasticsearch 中支持的数据类型非常丰富,关键的如下:
- String 类型
- text:可分词
- keyword:不可分词,数据会作为完整字段进行匹配
- Numerical:数值类型
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
# index
- 是否索引
- 默认为 true,不进行任何配置,所有字段都会被索引
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索
# store
是否将数据进行独立存储
- 原始的文本会存储在
_source里面,默认情况下其他提取出来的字段都不是独立存储 的,是从_source里面提取出来的
- 原始的文本会存储在
默认为false
设置为true,可以独立的存储某个字段
- 获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置
# analyzer
分词器,这里的 ik_max_word 即使用 ik 分词器,后面会有专门的章节学习
# 问题
如果事先已经定义了mapping,插入的文档有mapping没有覆盖到的字段,mapping情况如何?
如student2的mapping实现定义如下
{
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "text",
"index": true
},
"age":{
"type": "long",
"index": true
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
插入的文档如下,增加了address 和 nickname 字段
{
"name":"zhangsan",
"nickname":"zhangsan",
"sex":"男",
"age":30,
"address": "hefei"
}
1
2
3
4
5
6
7
2
3
4
5
6
7
查询的mapping如下
- address字段本身是text字段,可以被模糊查询
- address字段的
fields中增加一个名为keyworkd的属性,该属性的type是keyword- 可使用address.keyword进行精确匹配
{
"student2": {
"mappings": {
"properties": {
"address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long",
"index": false
},
"name": {
"type": "text"
},
"nickname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "text",
"index": false
}
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
Last Updated: 2022/02/05, 15:58:51